The wonderful world of SAT solvers
Imagine a circuit designer wants to verify the accuracy of a specific computation before it goes into production, and imagine a college trying to find the best way to schedule all their exams. On the surface, the problems seem pretty different, but the two are both instances of the same problem: SAT, or Boolean satisfiability.
Look at this statement: (A or B) and (not A or B). Determining which inputs make this statement true would be a SAT problem. Trivially, the given statement depends only on B being true, as A being either true or false satisfies only one of the statements, while B being true satisfies both. However, when playing around with an arbitrary number of inputs, the problem's difficulty becomes increasingly apparent. The problem is so hard it’s been proven NP-complete by the Cook-Levin Theorem.
In computer science, NP-complete problems are considered the hardest problems with quickly verifiable solutions. However, just because the solutions are quickly verifiable doesn’t necessarily mean the problem itself can be solved quickly. This is the essence of the P versus NP problem, one of the biggest unsolved problems in the field of computer science. If P doesn’t equal NP, then there is no polynomial algorithm that can solve all instances of an NP-complete problem.
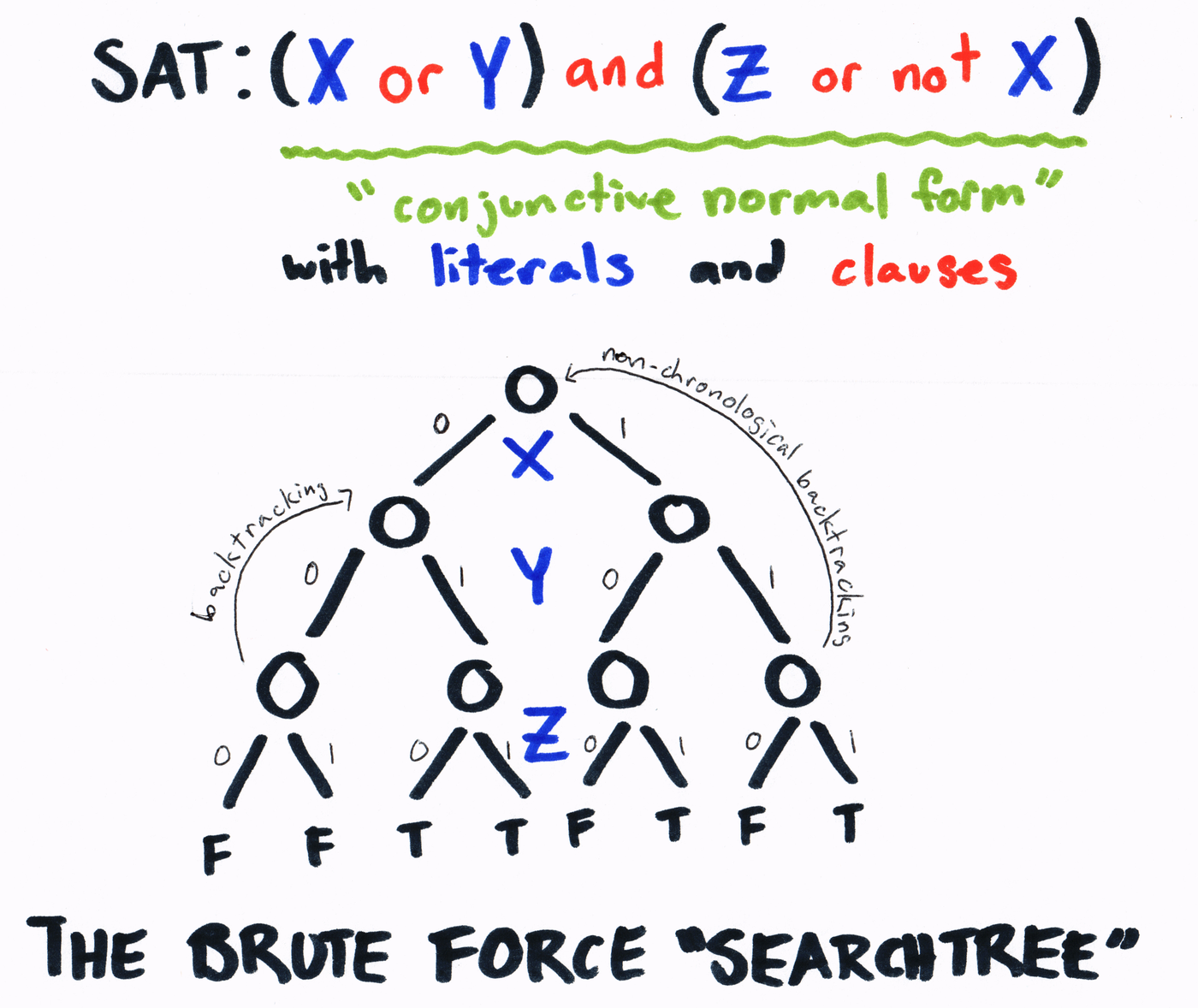
Before discussing algorithmic advancement, let's look at the formalism and structures hidden within this problem. The variables in the logical equation in the image above—X, Y, and Z—are referred to as “literals.” The statements between “or” and “or not” are its “clauses.” The input, taken as a whole, is said to be the “conjunctive normal form” of a Boolean statement.
Namely, to start solving SAT, a value is assumed for one of the variables, and this process continues until all variables are fully defined. At this point, we check to see if the resulting expression is true or false. If it's neither, we go back to our most recently defined variable and change it, going through all assignments. Although this type of brute-force search, called depth-first search, is ill-advised, it creates a more friendly visual aid.
Implicitly, this process outlines a binary tree, shown above. Left-handed “branches” indicate a variable as false, while right-handed “branches” indicate a variable as true. This doubles the number of branches at each level, and, since a level exists for each variable, the complexity is exponential.
Let’s optimize this algorithm. The first optimization to this algorithm is the “heuristic search.” The main idea of a heuristic search is to focus on the area most likely to provide the most bang-for-the-buck. In this case, whenever a literal is alone, it must be true. Also, whenever all but one of the literals are defined in a clause, the value of the remaining variable can be assumed by noting the assignments that would make the clause true.
It’s prudent to look out for these freebies in order to deduce the actual value of some literals in order to reduce the amount of guesswork. Computer scientists call this process "unit propagation." Another optimization to our algorithm would be to order the assignment of literals by how frequently they show up in the conjunctive form, i.e., if you see more X’s than Y’s, assign values to X’s first. Ultimately, this reduces the number of decisions required by our algorithm.
One issue we haven’t tackled yet is the cost of constantly iterating the conjunctive form, which can be thousands if not millions of clauses long. To reduce this cost, SAT solvers typically only keep track of two literals, called watched literals, as unit propagation is only possible if all but one variable remains. Thus, whenever unit propagation occurs, a watched literal is exchanged whenever possible. Formally, this class optimization defines the subclass of SAT solvers called “VSIDS,” popularized by the zChaff SAT Solver.
Trying to optimize beyond this point becomes increasingly difficult. The trick to understanding the additional optimization levels is to use our failures to increase our chance of success by searching non-sequentially from within our algorithm. In our search for a solution, it’s likely that specific configurations of literals will almost always lead to contradictions.
How can we use these contradictions to help us? By examining the contradiction, identifying which literals were involved, and tracing the contradiction to its roots using our tree diagram, we should be able to define these contradictions. It would be nice not to repeat such contradictions, but how do we do this?
This is actually much simpler than it first appears when considering the law of contrapositives. To illustrate, assume I always cry when receiving a failing grade. If I had not cried on a particular day, I could not have received a failing grade. These contradictions can thus add clauses to our original problem through their contrapositive forms.
You might be thinking that this seems like we’re increasing the size of our problem, not decreasing it. This is true, but this maneuver doesn’t actually increase our search space as these variables were already in the original problem. The benefit to these clauses is that they allow for more unit propagations, telling us whether a future guess is reasonable or unreasonable, paradoxically decreasing the search space. Recalling the tree diagram, this technique allows us to skip large portions of the tree in a process called non-chronological backtracking.
With this approach, however, the conjunctive form becomes littered with excess clauses. Thus, our algorithm needs to simplify and combine clauses when possible, a process called clause minimization. However, minimization can only go so far, and a problem-solver is forced to keep a few clauses. Luckily, there are some heuristics for evaluating which clauses to hold onto, but this is still an active area of research. Taken together, these techniques are examples of clause maintenance.
As a SAT problem is solved, some parts of the search space (our tree diagram) are better explored than others. Thus, discovering conflicts implicitly saves facts about the local context of the problem. These facts, as well as the last attempted solution, are beneficial because they allows the solving algorithm to resume work in a previously explored section of the search space. Storing this information is called the phase-saving heuristic. These additional optimizations define the class of SAT solvers called conflict-driven clause learning SAT solvers from which almost all modern SAT solvers derive.
As almost all computer science students are familiar with, randomization can be a tremendous asset to ensure optimal performance on a problem. There could be someone evil making our algorithm look bad by forcing inputs to take a certain, nonoptimal form, or, more realistically, just bad luck, that makes an algorithm perform suboptimally. Resolving this issue requires restarting the search somewhat periodically. This ensures that the contradictions and unit propagations the algorithm finds cover many clauses and literals within our tree. This allows our SAT solvers to consider what general trends are true while reducing the chances of getting stuck within an unlucky portion of the search.
Practically speaking, the implementation of this algorithm is an issue unto itself. To make the best SAT solver, one has to efficiently store the clauses, organize the search, encode and process the original problem to aid the SAT solver’s heuristics, and find a way to parallelize the search. All of these requirements are nontrivial to satisfy.
There is an extension to SAT solvers called Satisfiability Modulo Theories. SMTs aim to apply the reasoning ability of SAT solvers to more general problems in math and logic. For example, given two functions’ values, rules of composition, and properties, it can be determined whether their inputs will equal each other. However, this type of extension to SAT solvers requires us to program the rules and associated logic of the mathematical objects in question. We then need to build another application to orchestrate these systems of logic, called theories.
Not only can SAT solvers find optimal configurations, but they can also prove if such configurations are non-existent. SAT solvers can disprove statements by exhausting a search for a satisfying arrangement, or by noting the realization of unavoidable conflicts. Such a disproof is known as an UNSAT proof.
SAT, despite these advancements, is still an NP-complete problem and therefore takes exponential time to compute. However, there seems to be a hidden structure in SAT problems relevant to humans that separates them from randomly generated SAT instances. Therefore, we see that algorithms used to solve human-relevant problems perform exceptionally well when scaled to problems with millions of clauses and variables. The evolution of SAT solvers shows two quite remarkable things: Humans will find a way to overcomplicate anything, even something as simple as brute force search, and algorithms are very general tools, much simpler than one may fear, that are impactful even in areas the original designer had no understanding of.
 Editorial Notebook
Editorial Notebook